ピッチモデリング指標の解説
Stuff+、BotCmd、PitchPro、近年よく聞くようになったこれらの指標は一般的に「Pitch Modeling(ピッチモデリング)」指標と呼ばれています。
モデリング自体は昔からある概念ですし、もちろん野球においてもモデリングの性質を持った指標は多いです。
ただ、今回解説する、主に投手の出力(プロセス)に基づいたモデリングは、長年セイバーメトリクスを支えてきた打席や投球の結果(アウトカム)に基づいたモデリングとは意味合いに違いがあります。
ピッチモデリング指標とあえて表現する背景にはこのような文脈もあり(多分)、またそれが、プロセス情報の入手が困難だった時代に構築されたモデリング指標とは一線を画す存在となる理由でもあります。
機械学習とは
ピッチモデリング指標は機械学習を活用しています。
そもそも機械学習とは『データから規則性を学習し、未知のデータに対して予測や推定を行う手法』の総称です。
これには線形回帰やロジスティック回帰といった、セイバーメトリクスの文脈で初期から活用されてきた分析手法も含まれます。
ただ、それらをわざわざ機械学習と呼称することは少なく、一般的には Random Forest(ランダムフォレスト)や Neural Network(ニューラルネットワーク)といった、より複雑なアルゴリズムを指していることが多いです。
セイバーメトリクスファンは k-Nearest Neighbor algorithm(k近傍法、k-NN)は聞き馴染みがあるでしょう。
現在主流のピッチモデリング指標は全て、機械学習の手法の一つ、Gradient Boosting Decision Tree(勾配ブースティング決定木、GBDT)を活用しています。
GBDTとは
GBDTは有り難いことに名前がその手法を表しています。『勾配』を使って『ブースティング』を行う『決定木』といった感じですね。
GBDTは初めて聞く方も多いとは思いますので、名前に沿ってできるだけ簡潔にまとめます。
Gradient(勾配)
GBDTのゴールを表しているのがこの語句です。
ここで言う勾配も屋根や道路で使われる傾きと同じような意味です(スカラーではなくベクトルですが)。
そして機械学習における勾配とは、損失関数(予測誤差の大きさを表す関数)の増加方向と大きさを表すベクトルであり、GBDTでは勾配と逆方向に進む=誤差を減らすことをゴールとする勾配降下法をこの後紹介するブースティング決定木によって実現しています。
勾配降下法については、線形回帰をはじめとし、多くの機械学習で採用されている、言わば土台のようなものです。
GBDTはその勾配降下法の中身が特殊です、という話をこれからしていきます。
Boosting(ブースティング)
ブースティングは『弱い学習器を逐次的に学習・統合することで、全体として高性能なモデルを作る』手法です。
この手法の主眼は、前のモデルの系統的な誤差(バイアス)を後のモデルが修正していくことにあります。
また、弱い学習器を多数使用することで、それぞれのモデルが違う方向に間違ってくれるため、結果的にノイズが平準化され、過学習を防ぐことができます。
GBDTは、このブースティングの過程に先に述べた勾配降下法を取り入れたという点で、機械学習において革新的なアルゴリズムとなりました。
ちなみに、ブースティングのような複数のモデルを組み合わせる手法=アンサンブル学習には、**モデルの安定性や信頼区間を得ることに焦点を置いている Bagging(バギング)**と呼ばれるものもあります。
逐次的に学習するブースティングとは対照的に並列に学習することで分散(バリアンス)が低減されます。
モデルの性能を高める(バイアスを低減する)ことに焦点を置いているブースティングとともに、統計学的に無視できない観点ですので記憶の片隅に入れておくことをおすすめします。
▶︎フレーミング指標の解説でバギングについても少しだけ触れています
Decision Tree(決定木)
最後に弱学習器としてブースティングに使用している決定木の説明です。
決定木は一言で言うと『条件分岐の繰り返しで予測する』手法です。
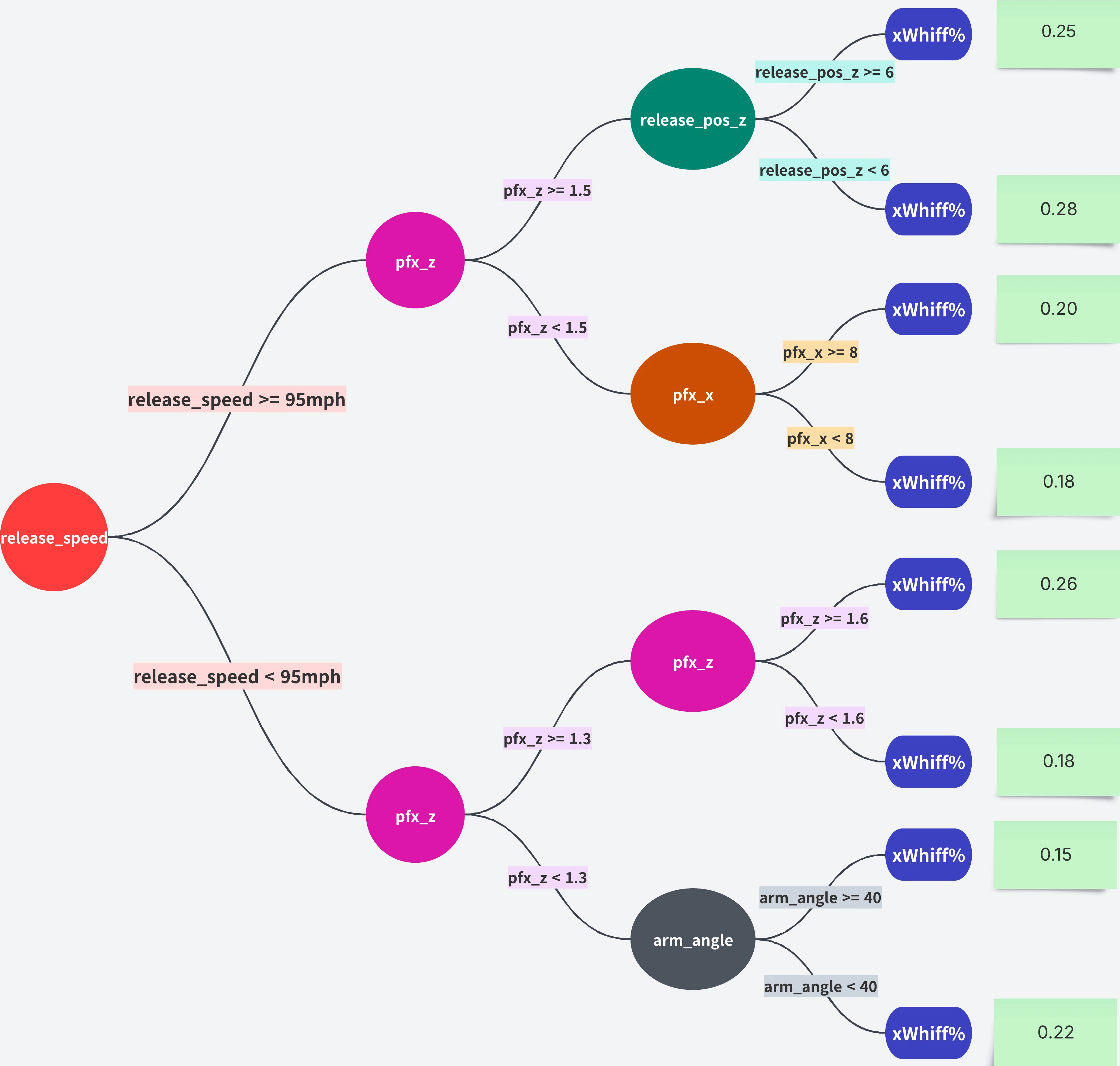
上記のイメージ図からも想像できるとは思いますが、決定木は弱学習器を多数作るブースティングにかなり向いています。
分岐の数(深さ)を制限するだけで簡単かつ確実に弱学習器を作れます。 上記の図で言うと、最初の pfx_z の条件で分岐を終えるだけで(全くの無能ではない)弱い予測モデルができることは想像しやすいと思います。
また、条件分岐という特徴により特徴量(≒説明変数)のスケーリングが不要になりますし、非線形な関係はもちろん、カテゴリ変数や段階的な関係も捉えやすくなります。野球分析に向いている匂いがプンプンしてきました。
GBDTはブースティングの学習器として決定木を採用し、その高い実用性を実現しています。
野球におけるGBDTの強み
では先述したGBDTの特徴は野球分析においてどのような強みを持つでしょうか。
以下に野球分析において有り難い要素を並べてみました。
- 特徴量のスケーリングが不要
- 決定木では特徴量の大小関係(順序)に基づいて分割する
- 欠損値や外れ値の処理が比較的優れている
- 分割に焦点を置く決定木では分布や外れ値の影響を受けにくい
- 段階的な変数に強い
- 決定木は条件分岐を繰り返す構造なので特徴量間の複雑な関係性に強い
- 特徴量の交互作用を捕捉できる
- 決定木は条件分岐ごとに異なる特徴量を選ぶため、モデル全体として特徴量間の主要な交互作用を捕捉できる(ライブラリによって制約はある)
- カテゴリ変数に強い
- ダミー変数化せずに直接利用でき、次元の増加が抑えられ、多重共線性を起こしにくい(ライブラリによって差はある)
- 表形式データに強い
- 条件分岐がベースにある決定木と表形式データは相性が良い
- 無駄な特徴量を入れても精度が落ちにくい
- 勾配に基づいて誤差を修正するため、予測に影響を与えない特徴量は後の条件分岐で選択されにくくなる
- 大規模データに強い
- 現代のライブラリでは計算効率が極限まで高められている
- 特徴量重要度を明確に示せる
- GBDTはモデル全体で、各特徴量がどれだけ損失を減少させたか、または予測に寄与したかを累積的に評価できる
- 解釈性がそこまで低くはない
- 全体像を把握するのは困難だが、他の複雑なアルゴリズムと比較して、予測結果の筋道は比較的理解しやすい
- 多クラス分類に対応できる
- 勾配降下法の汎用性とブースティングの逐次的な修正により、複数の確率を同時に予測できる
まず注目するポイントとしては事前のデータ整形のプレッシャーが抑えられる点でしょう。
例えば、機械学習において知名度の高いニューラルネットワークでは事前のスケーリングが必須になりますし、深層学習(ディープラーニング)ではより高度な正規化が求められます。野球データにおいて特徴量ごとに適した正規化を行うのはそれだけで骨が折れます。
そしていわゆる重み付けではなく条件分岐で誤差を減らしていくので、利き手の左右や球場といったカテゴリ変数、そしてピッチカウントと打者の積極性といった(非線形かつ滑らかでない)段階的な変化、またArm Angle × IVBといった交互作用への対応に強くなります。
算出方法
では実際にモデルを組んである程度の流れも説明していきます。
訓練データとテストデータ
訓練データは2021〜2023年の欠損値を除くMLBのデータとします。
2024〜2025年をテストデータとし、記述性や予測性を評価します。
サブモデル
サブモデルは以下の4つとします。
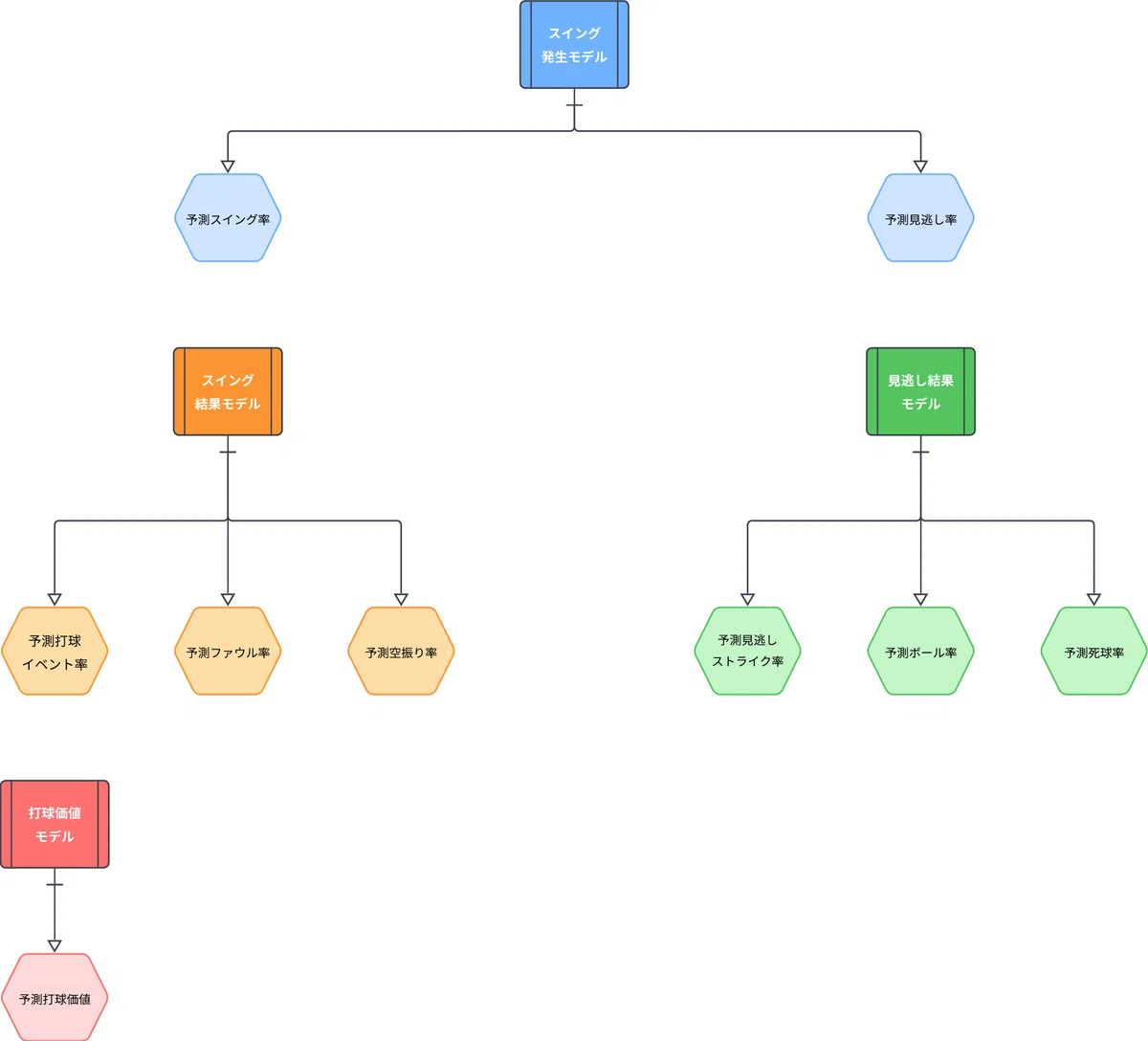
もちろん、わざわざサブモデルに展開せず、直接得点価値を推定する手法も間違いではないですし、実際にその手法を取っている野良のセイバリストもいます。ただ現状、主要データサイトのピッチモデリング指標は全て野球をサブモデルに展開しています。
理由としてはいくつかありますが、まずは精度の向上という点。
サブモデルに展開することでサブモデルごとに最適な特徴量や閾値が選択されます。 スイング時や見逃し時では重要となる特徴量は当然変わってきますので精度向上には必要です。
また野球において各イベントは均衡しておらず、発生確率に差異が生じます。サブモデルへの展開でその不均衡を穏やかにすることができます。
デバックがしやすいのもメリットでしょう。
そして解釈性の向上も理由の一つです。
順序立てて予測していくことで、各段階での特徴量重要度から野球に対する理解度の向上を望めます。
また得点価値の予測ではなく、各事象の確率予測という点では、選手のタイプや状況によって変化するレバレッジへの対応への一助となる可能性を秘めています。
特徴量
使用した特徴量は以下です。
もちろんこれは一例であり、目的によって特徴量の取捨選択はできますし、更なる精度向上のために各サブモデルで特徴量を変える選択肢もあります。
◆ Stuff モデル
- 打席
- 身長
- アームアングル
- 球速
- 加速度(x軸、z軸)
- リリースポイント(x軸、z軸)
- 変化量から予測される回転軸と実際の回転軸の差
- 回転効率
- 主要速球との球速差
- 主要速球との加速度差(x軸、z軸)
◆ Location モデル
- 打席
- 投球座標(x軸、z軸)
◆ Pitch モデル
- 打席
- 身長
- アームアングル
- 球速
- 加速度(x軸、z軸)
- リリースポイント(x軸、z軸)
- 変化量から予測される回転軸と実際の回転軸の差
- 回転効率
- 主要速球との球速差
- 主要速球との加速度差(x軸、z軸)
- 投球座標(x軸、z軸)
利き手調整済み、ピッチカウント効果は事前に補正
そして先述したようにGBDTでは特徴量重要度を算出することができます。
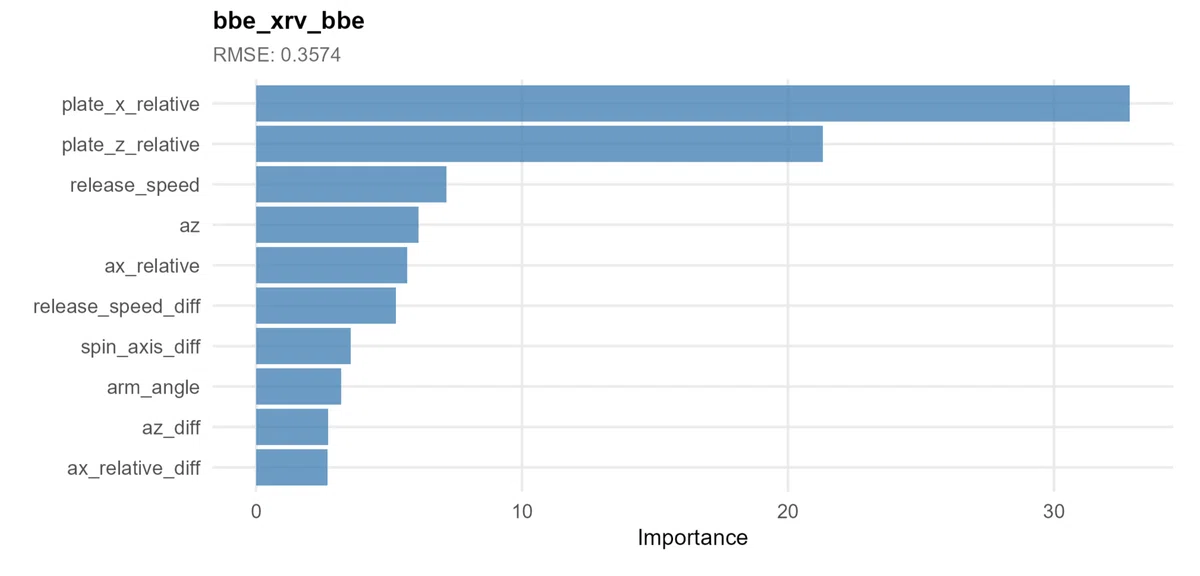
ただ特徴量重要度にももちろん欠点はあります。
基本的な手法ですと、条件分岐に出現しやすい多カテゴリや大スケールの特徴量を過大評価してしまったり、未知のデータを対象としているわけではないので実際のモデル性能への貢献度とするのはリスクがあったり……。
上記の図はそれらの欠点を改善した算出方法ではありますが、それでも特徴量間の交互作用を捉えきれなかったり、あくまでも全体的な話で個別的な解釈には使えなかったり……。
ライブラリ
ライブラリの選択です。
GBDTの有名なライブラリは XGBoost、LightGBM、CatBoost の三者かと思います。
同じGBDTでも各ライブラリには違いがあります。
(流石に退屈だと思うので)この違いについては割愛しますが、例えば決定木の説明で出したイメージ図は XGBoost が近いです。
LightGBM は木が対称に広がっていかず重要な枝だけ深くなったりします(もちろん過学習のリスクは上がる)。
対して CatBoost は特徴量の選択や閾値の設定まで対称とするので過学習には強くなりやすいです。
その結果、処理速度は LightGBM が強く CatBoost が弱かったり。
ただ、全体的な精度については優劣はないものと思っていただいて構いません(プレイヤーの設定やデータの特徴次第)。
各サブモデルを先に示した特徴量で実行します。
今回は(微差ではありますが)一番来シーズンの予測精度が高かった CatBoost を採用しました。
得点価値予測
得られた各イベントの予測確率と各イベントの得点価値、そして打球イベントの予測得点価値を組み合わせて全体的な予測得点価値を算出します。
Stuff モデルは投球座標の影響を減らしたいので、スイング結果モデルと打球価値モデルのみ考慮します。
性能
主要データサイトのピッチモデリング指標と比較した性能を見ておきましょう。とりあえず指標名は「Pitch New」、「Stuff New」としておきます。
まずは記述性です。
目的変数は同年の Run Value(レバレッジあり)とします。
| 指標名 | 相関係数 |
|---|---|
| PitchPro | 0.530 |
| Pitching+ | 0.504 |
| Pitch New | 0.495 |
| StuffPro | 0.478 |
| botOvr | 0.455 |
| botStf | 0.433 |
| Stuff+ | 0.429 |
| Stuff New | 0.411 |
2024〜2025 MLB(1000球以上)| n = 537 Data: FanGraphs, Baseball Prospectus, Baseball Savant
記述性についてはそれほど拘りたくありません。
もちろん、ここに載せないほど低い Location モデルたちはそもそもの野球的な意味を問われてしまいますが、プロセス情報に基づいたモデリング指標である以上、アウトカム情報に基づいたそれより記述性は低くならないなら、それはどちらかの指標に不備がある可能性が高いです。
簡単に言うと、アラエスのコンタクトやウォルナーの空振りをより記述するモデルが野球的に正しいとは言えません。
次に一貫性です。
目的変数は翌年の同指標とします。
| 指標名 | 相関係数 |
|---|---|
| Stuff New | 0.863 |
| botStf | 0.843 |
| StuffPro | 0.809 |
| Pitch New | 0.783 |
| Stuff+ | 0.765 |
| botOvr | 0.688 |
| Pitching+ | 0.681 |
| PitchPro | 0.673 |
2024〜2025 MLB(1000球以上)| n = 153 Data: FanGraphs, Baseball Prospectus, Baseball Savant
不備の少ない設計では、記述性と一貫性は基本的にはトレードオフとなります。
記述性で一番評価が低かった Stuff New や Pitchカテゴリーではそこまで高くなかった Pitch New の一貫性が目立ちます。
最後に予測性です。
目的変数は翌年の Run Value(レバレッジあり)とします。
| 指標名 | 相関係数 |
|---|---|
| Pitch New | 0.408 |
| Pitching+ | 0.395 |
| Stuff New | 0.392 |
| StuffPro | 0.379 |
| botStf | 0.377 |
| PitchPro | 0.358 |
| Stuff+ | 0.343 |
| botOvr | 0.294 |
2024〜2025 MLB(1000球以上)| n = 153 Data: FanGraphs, Baseball Prospectus, Baseball Savant
予測性は実質的に記述性と一貫性の総合評価です。
記述性はそこまで高くなかった Pitch New と Stuff New の評価が高くなっています。
記述性と予測性のバランスが良い Pitching+ や StuffPro は感情的にも機能的にも有り難いでしょう。
逆に言うと、Pitch系のカテゴリーでは記述性も低く予測性も低い BotOvr は何らかの見直しは必要かもしれません。
ピッチモデリング指標を活かした分析
では軽くではありますが、ピッチモデリング指標の活かし方についても触れておきます。
この note 内で『革命的な指標』だとか、『一線を画す存在』だとか仰々しい表現をしましたが、「メイソン・ミラーの Stuff 凄い!」だけで終わることが多い現状ではその域には達していないでしょう。
ピッチモデリング指標の強み
先に述べた通り、ピッチモデリング指標の強みは『主に投手の出力情報に基づいている』点です。
くどいようですが、これが意味するのは他の選手(や調整次第では他の環境)の情報が薄いという点です。
責任の所在を明らかにしやすい野球という競技においても、当該選手のみによって生み出される情報は限られるものでした。
その点でトラッキングデータは革命であり、その中でも高精度なホークアイデータを活用したピッチモデリング指標は、過去に難しかったアウトカムの分解、いわゆる責任分配、さらには因果推論まで進むためのペダルとなるべきだと考えています。
有効活用しているセイバリストの紹介
自身でモデルを構築しアウトプットするセイバリストが増えた近年においても、その観点において精力的だなと感じる方はほとんどいないです。
例を挙げておきます。
TTOPの分解
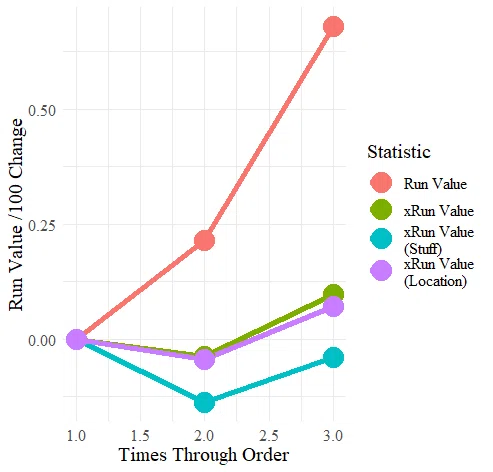
Pitching Bot 開発者の Cameron Grove によるTTOP(周回効果)の分解は有名かと思います。
投手と打者と守備者とその他環境によって生み出される周回効果(対戦回数が増えるほどRVが増加する)から、投手のプロセス情報を抽出することによって、打者の"慣れ"が関係するという仮説に近づくことができます。
PFの分解
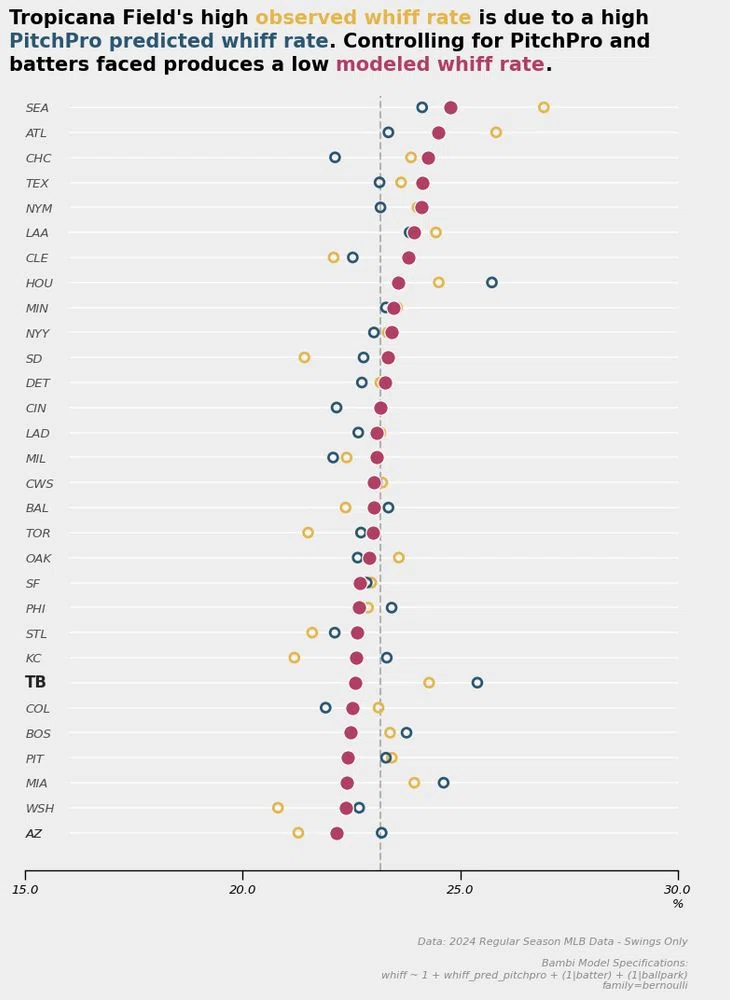
プロセス情報を活かした分析において群を抜いて精力的だと感じているのが、PitchPro、StuffPro 開発者の Stephen Sutton-Brown(SSB)。
上記の例では、空振りPark Factor が大きい T-Mobile Park と Tropicana Field はその因果は全く違う可能性が示唆されています。
SSBについてはこれはほんの一例で、ピッチモデリング指標を活かした責任分配から投球戦略、また打者におけるプロセス要素の強い変数を活かした分析等、個人的にかなり理想に近いアウトプットをしていると感じています。
もちろん、その精力さ故に交絡因子の見落とし等もあるとは思いますが、その点についてトップクラスの Tom Tango を心の中に飼い、アクセル(SSB)とブレーキ(Tango)をうまく使いながら探究を深めていきたいなと最近は考えています。
ホームアドバンテージの責任分配
では、簡単にではありますが、自分もメジャーなテーマをプロセス情報を活かして調べてみます。
他の競技と同様、野球にもホームアドバンテージがあることはよく知られているかと思います。
おおよそホームチームの勝率が 53% 〜 54% となる傾向で、例えばこれを Pythagenpat に組み込むと1試合あたりのPitch Valueは +0.14 〜 +0.19 ほどとなります。
2024年と2025年では以下のようになっています。
| 年 | ホーム勝率 | ホームPV/G |
|---|---|---|
| 2024 | 52.2% | 0.124 |
| 2025 | 54.3% | 0.157 |
Data: Baseball Reference
この Pitch Value の差を投球、打撃、守備に配分してみましょう。
算出方法は以下です。
◆ 投球 ホームでの予測 Pitch Value - アウェイでの予測 Pitch Value
◆ 打撃 ホームでの xRun Value - ホームでの予測 Run Value - アウェイでの xRun Value - アウェイでの予測 Run Value
◆ 守備 ホームでの xRun Value bip - ホームでの Run Value bip - アウェイでの xRun Value bip - アウェイでの Run Value bip
予測 Pitch(Run)Value は Pitch New で予測した Pitch(Run)Value xRun Value は打球部分(垂直打球角度、水平打球角度、飛距離)を k-NN でモデリングしたもの
投手が投球を始めてからイベントが確定するまでのプロセスは、投手 ⇒ 打者 ⇒ 守備です(厳密に言うと気候等の環境や審判が介入する)。
投手と打者のプロセス情報(ピッチモデリング、打球モデリング)をそれぞれの段階で切り離すことで、より野球的な責任分配が可能になります。
多少の誤差は生じますのでそれらを正規化した比率が以下です。
| 年 | 投球 | 打撃 | 守備 |
|---|---|---|---|
| 2021 | 24.7% | 40.4% | 34.8% |
| 2022 | 32.9% | 45.2% | 22.0% |
| 2023 | 20.1% | 49.8% | 30.1% |
| 2024 | 30.2% | 63.9% | 5.9% |
| 2025 | 17.7% | 55.8% | 26.5% |
1シーズンあたり7万球ほどあるとは言え、2021〜2023年は学習データである点に注意 Data: Baseball Savant
年によってバラつきはありますが、一貫して打撃の貢献割合が大きくなっています。
様々な側面から語られるホームアドバンテージですが、ホーム球場で投手がより良い投球をしている以上に打者がより良い打撃をしている可能性が高そうです。
示唆される要因としては、バックスクリーンを含むボールの見え方への慣れ、球場特有の変化量への慣れでしょうか。
もちろん、この算出方法が考慮していない要素は多々あります(例えば打撃は審判の影響が 3%程度入っていそう)。
ただ、それらを考慮するのもプロセス情報の入手とモデルへの組み込み、そして切り離しで可能になります。一応、過去に似たことはやっていたります。
▶︎ポストシーズンの低いBABIPはどこから??
強みを活かした分析あれこれ
今回はピッチモデリング指標の活用法として、責任分配に主眼を置きましたが、他にも活かせる文脈は存在します。
対象階層でのアウトカムが存在しない投手
実際にしているアナリストも多いですが、マイナーリーガーやアマチュアの投手など、対象階層(MLB等)での結果が存在しない投手の評価です。
正直なところ対象階層での結果が存在する投手は K-BB% なり SIERA なり見てれば良いですが、そうでない投手の場合、対象階層での貢献を予測する上で所属階層のノイズ(打者が極端に変化球に弱い等)を除去できる指標の優位性が際立ちます。
それらに通ずる話として、怪我復帰後やフォーム変更後等、対象階層でのサンプルの信頼性が低いと判断できる場合もアウトカムに頼らない指標の利用価値は高まります。
特徴量の操作
先述しましたが、目的によって特徴量の取捨選択ができる点も強みです。
例えば、Tropicana Field を本拠地にしている投手と Coors Field を本拠地にしている投手を特徴量として変化量が入っているピッチモデリング指標で評価して良いでしょうか?
マウンドからホームに追い風が吹かない屋内球場とそもそもの空気密度の小さい高地の球場において、変化量という特徴量には能力を測る上でノイズとなる環境要素が強く含まれてしまいます。
目的が投手の能力を推定することであるなら、上記の問題に対処する必要はあります。MLBの投手なら PF で補正するというのも手段の一つとなりますが、このような事例はマイナーやアマチュア、海外リーグの投手の評価をする際に必ず直面する問題です。
そのような投手の能力を評価するという目的のもとに、環境に左右されにくいプロセス情報を駆使したモデルを構築できるのも強みです。
またピッチモデリング指標に対して、「球種構成」「ピッチトンネル」「シークエンス」等が考慮されていないという反応もいくつか見受けられます。
ただ、それらに関してもモデルに組み込むことは可能ですし、実際に「主要速球との球速差」等を特徴量に含めているピッチモデリング指標は多いです。
そして、あくまでも Pitch レベルに主眼を置いたモデル(現状はそのようなモデルも多い)と球種構成等 Pitching 的な要素も考慮に入れたモデルを比較して、その乖離が大きい投手を探るといった使い方ができるのも魅力です。
球種別の評価
これはピッチモデリング指標の特徴というよりかは、アウトカム情報に基づく指標の網羅性の話になってきますが、役割の違う球種を一元的に評価できるモデリング要素の強い指標がまだ少ないです(その精査もやっていきたいですね)。
集計されたスタッツをモデリングする指標が多い中、モデリングされたスタッツを集計するという特徴は球種別の評価には(注意点はありますが)適しています。
おわりに
今回はピッチモデリング指標について冗長にならない程度に解説をしてみました。
比較的新しく、難しい指標だからこそ陥る短絡的な使用法への警笛も兼ねた note となりましたが、どんな指標にも算出方法がある限り、その使用法はリーダーボードを眺めるだけで留まるものではないという点に相違はありません。
野球の構造的な理解から、あらゆる指標の算出方法の背後にある演繹的、帰納的な理論を読み取り、またそれをさらなる野球の構造的な理解に活かす。
その積み重ねがお馴染みの FanGraphs のリーダーボードや Baseball Savant の選手トップページをまた違った色に染めてくれるものとも思います。
現状、そのような『野球の探究』について知見を集めるためには英語文献にも触手を伸ばす必要はありますが、この度新刊が出版された「デルタ・ベースボール・リポート」はそのジャンルの貴重な日本語文献枠でしょう。
今回紹介したようなモデリング指標を使った考察も掲載されていますので、最後にそちらの宣伝とともにこの note を締めたいと思います。
参考文献
- Understanding Machine Learning: From Theory to Algorithms - Shalev-Shwartz, S., Ben-David, S. (2014)
- Greedy function approximation: A gradient boosting machine. - Friedman, J. H. (2001)
- XGBoost: A Scalable Tree Boosting System - Chen, T., & Guestrin, C. (2016)
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree - Ke, G., et al. (2017)
- CatBoost: unbiased boosting with categorical features - Prokhorenkova, L., et al. (2018)
- PitchingBot Pitch Modeling Primer - FanGraphs
- Introducing StuffPro and PitchPro - Baseball Prospectus
- Stuff+ is updated!